
Introduction
In the first part of the Reconnaissance blog, we learned about different tools and techniques that can be used for OSINT.
In this part, we continue the journey and learn further about Reconnaissance. Following are the main topics that are covered in this article –
- How to query DNS records?
- What is DNS cache snooping?
- What is DNS Zone Transfer?
- Using Google Dork
- Querying Shodan
Understanding DNS Record
Like the WHOIS database registrar’s domain registration information, DNS records may include information about individual domain assets such as the fully qualified domain name (FQDN) and IP address.
The DNS protocol’s requirements are described in RFC 1035 (https://www.ietf.org/rfc/rfc1035.txt). The DNS service implements the protocol’s criteria and is hosted on a specific name server (NS).
BIND is a DNS server software programme that is extensively used on the Internet.
For all Unix-like operating systems, BIND is the de facto standard. A DNS resolver, a DNS root server, and an authoritative DNS server are the three kinds of DNS servers that are used for hostname and IP address resolution in a Domain Name System (DNS).
When a user tries to visit a website like www.google.com, the client sends a DNS query to the company’s root DNS server. If the domain name cannot be identified, the query is directed to the authoritative DNS server, which is the DNS hierarchy’s last stop.
The DNS resolver caches the answer when a successful query is returned to the organization’s root name server, so that future queries for the same domain name may be resolved using the DNS cache.
A DNS name server normally manages the following ten categories of records:
- A – hostname and IPv4 address mapping record
- AAAA – IPv6 address mapping record; stores hostname and IPv6 address
- CNAME – Record of the canonical name; an alias for a different hostname
- Name server record (NS); indicates a name server that is authoritative.
- PTR – reverse-lookup pointer record; provides the hostname for a given IP address
- CERT – Certificate record; specifies an SMTP mail server
- MX – Mail exchanger record; specifies an SMTP mail server
- SRV – Record of SRV Service Locations; akin to MX, but for different protocols
- TXT – a text; Account information, server, network, or data centre information are examples of human-readable data.
- SOA – Administrative information concerning a DNS zone; start of authority record
Configuring DNS name servers creates zones. A DNS zone is a segment of the domain name space that enables fine-grained control over resources inside the domain, such as authoritative name servers that provide IP address information for a requested hostname.
For a domain’s hostnames, DNS zone files are used to give accurate lookup information. Forward-lookup zones convert hostnames to IP addresses, whereas reverse-lookup zones translate IP addresses to hostnames.
A firm that does business on the Internet will have its own second-level domain (for example, example.com) as well as subdomains (for example, sub.example.com) to help separate commercial operations or geographical locations, depending on the size of the organisation.
The bulk of top-level domains (TLDs), such as.com and.org, are managed by ICANN/IANA. Visit https://ns1.com/resources for additional information on how DNS works.
DNS Query Example
To query domain name servers in Linux, use the nslookup command-line utility. The non-interactive mode is used to print merely a host’s or domain’s name and required information.
The interactive mode is used to request information from name servers about different hosts and domains, or to simply print a list of hosts inside a domain.

What is DNS Cache Snooping?
The capacity of a DNS resolver to cache successful lookup requests is one of the properties of a DNS.
This procedure speeds up domain name resolution by removing the requirement for an organization’s DNS server to contact the target domain’s authoritative server to resolve the IP address for the hostname.
A time to live (TTL) value is used by DNS servers to determine how long they will hold a record in their cache. With a TTL of 86400 seconds, a record might be cached for up to 24 hours. Using both nonrecursive and recursive lookups, you may determine which hostnames a DNS server has resolved.
When a client submits a query to resolve an IP address for a particular hostname, the DNS resolver is designed to send requests to consecutive DNS servers until it finds the proper authoritative server to execute the client’s request.
This is referred to as a DNS recursive query. When the DNS resolver already knows the information the client is asking (i.e., it’s cached) or at the very least the relevant authoritative server to query for the information, it’s called a nonrecursive query.
You may try to query from a DNS server’s cache using the nslookup command. nslookup requests recursion from the name servers it queries by default.
You may use the nslookup command to do an A record lookup against the server’s resolver cache using a nonrecursive query with the -norecurse and -type command arguments.
The DNS server has previously resolved google.com but not bing.com, as can be seen. If you run this search against a target’s DNS server numerous times over the course of a week, you may be able to figure out which Internet search engines or social networking platforms the client organisation prefers or allows.
During a pentest engagement, knowing which external websites, apps, and/or resources a business enables its users to access might help you increase your chances of success when launching attacks like social engineering or phishing campaigns.
You may be able to deceive your target audience by making your activities look legitimate when the demands come from well-known and reputable sources.
A query against the resolver cache that isn’t recursive.

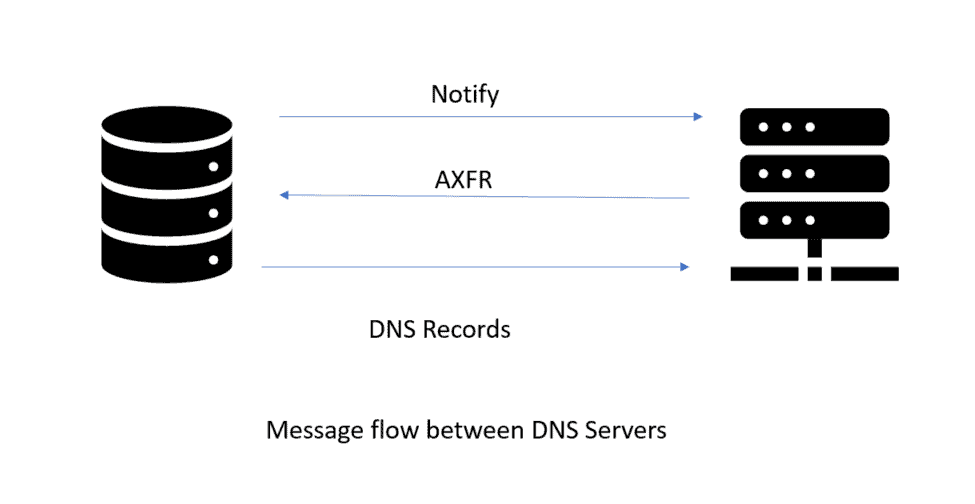
What is DNS Zone Transfer?
Larger businesses may use numerous DNS servers, or zones, to describe the organization’s structure or to guarantee continuity when a DNS server is unavailable for maintenance or fails.
Primary and secondary DNS servers are the terms used to describe these servers. System administrators may set their name servers to conduct a DNS zone transfer to duplicate the database information across all DNS servers within the company, ensuring that records between DNS servers are consistent.
A zone transfer is a client-server transaction that communicates with the server service on TCP port 53 using the Transmission Control Protocol (TCP). The service might be exposed to unauthorised access if the DNS server does not specify servers that can extract data for that zone.
You may perform further DNS research and exploit DNS zone transfer vulnerabilities using commands like dig to discover more about an organization’s network, including internal hostnames and IP addresses.
Some businesses may choose a naming convention that includes the host’s purpose or even the operating system in the name. A web server, for example, maybe called “webserver,” a domain controller, “dc01.win2k12,” or a file server, “fs01.win2k16.”
Although this type of naming convention may make it easier for system administrators to determine a host’s function simply by looking at its name, it also gives attackers the advantage of knowing what the target host is before they even survey the network’s ports and services, potentially reducing the number of steps required to attack and compromise a network resource.
Using dig for DNS Lookup
Dig, a DNS lookup application, is a versatile tool for querying DNS name servers. Kali Linux comes with it pre-installed. The command’s fundamental command-line syntax is as follows:
# dig @[name server] [domain name] [record type]
You might use the following command to look for all MX (mail host) records for a domain:
# dig +nocomments @192.168.1.1 example.com MX

If a DNS server enables DNS transfers and has TCP port 53 open, you may test if it permits anonymous zone transfers across the network by using the following syntax, the result of which is given next:
# dig +nocomments @192.168.1.1 example.com -t AXFR
This will retrieve all records for a given domain. In the results you can find useful information such as the start of authority (SOA), service location (SRV) records for other services on the network, and aliases (CNAME) that point to other hosts in the domain. From here, you can gather valuable information about the topology of the target organization and the role each host plays in the network.
Using Google Search for OSINT
Search engines have given a mechanism for users to search and get information from Internet databases that correlate to keywords or characters in the user’s query during the last several decades.
Search engines such as Google Search (www.google.com), Microsoft Bing (www.bing.com), and DuckDuckGo (www.duckduckgo.com) use automated computer programmes known as web crawlers to index web pages and material available on the Internet.
These tools seek for a robots.txt file in the web server’s root directory first. If the file exists, the web crawler software’s search and indexing capabilities are limited to directory locations not indicated in the file; if the file does not exist, the programme scrapes material, follows links, and so on until the process is finished.
This section focuses primarily on Google Search and explores some of its basic and advanced search capabilities that are useful for open source intelligence discovery.
Because Google has by far the largest market share and provides a passive approach to obtaining information, this section focuses on Google Search and explores some of its basic and advanced search capabilities that are helpful for open source intelligence discovery.
A robots.txt file provides a “User-agent,” which indicates a specific web crawler (e.g., Googlebot, or the * wildcard for all bots), as well as search directives, which tell the web crawler what indexing is permitted and banned.
The web crawler believes the search is authorised unless the “Disallow” is explicitly mentioned. The following is an example of a robots.txt file:
User-agent: *
Disallow: /cgi-bin/
Disallow: /scripts/
Disallow: /admin
Disallow: /docs
Disallow: /wp-admin/
A useful feature of search engines is that searches are case-insensitive, meaning you don’t need to know if a letter is capitalized or not. One of the most powerful features of Google that can help you narrow the search criteria for your target is the use of Google search operators and directives.
| Basic | Operator | Example | Purpose |
| Operators | “ ” | “penetration testing” | Finds exact match |
| OR | penetration OR testing | Finds any match that includes either term (Google defaults to AND, finding matches that include both terms) | |
| 1 | penetration | testing | Similar to OR operator | |
| * | penetration* | Acts as a wildcard to match on any word | |
| intitle: | intitle:“Index Of” intitle:index.of | Searches only in page title | |
| inurl: | inurl: “password” | Looks for word/phrase in URL | |
| intext: | intext: “password” | Searches word/phrase in body of page/document | |
| filetype: | filetype:txt | Matches only a specific file type and typically requires another search operator, such as “site” | |
| site: | site: “www.example.com” site:“.org” | Searches only a specific site or domain |
You may target particular content from many domains or web servers by combining these operators. For example, you might use the following syntax to run a Google search for.edu (educational) websites that have a PowerPoint file:
site:.edu filetype:ppt
The indexing of online pages displays a directory listing of a certain web directory. This may be useful during a pentest since it may reveal sites and material that were previously hidden from the web crawler. If you wanted to search for directory indexing against a target’s domain on Google, you might use the following syntax:
site:apache.org intitle:index.of
Some websites may be designed to be susceptible to certain sorts of searches in order to entice hackers to visit the pages, either for malevolent intentions (e.g., abusing the user’s web browser) or for research and investigative objectives (e.g., using honeypots). In the search results, Google offers a “cached” drop-down arrow next to the site URL.
You may get the cached version of the page by clicking it (when Google last indexed the page). Rather than clicking the link to get to the real website, this is a safer and more anonymous method to explore the material.
The Google Hacking Database (GHDB), also known as Google Dorks (https://www.exploit-db.com/google-hacking-database), is a web-based resource that pentesters may use to learn about inventive search tactics that might help them find susceptible systems and information disclosure vulnerabilities.
The GHDB was founded by Johnny Long, a security researcher, but is currently managed by Exploit-DB. The GHDB has over 1000 search categories, however as Internet security improves, some of them are being phased out. Let’s have a look at a couple approaches from the GHDB that are still useful.
As previously stated, the robots.txt file gives crawlers specific “Disallow” instructions to restrict them from crawling the website. The main problem is that attackers have access to the robots.txt file, which allows them to determine which web directories are critical to a business. Take a look at the Google search criteria below:
site:.edu inurl:robots.txt intext:Disallow
This will produce a list of.edu websites that have “robots.txt” in the URL and “Disallow” in the body of the page content. You’ll find a list of directories that aren’t authorised to be searched by a web crawler if you go to the “cached” Google search for one of the URLs that was returned in your search.
This information might aid in narrowing the attack surface against a target web server during a pentest, such as when brute forcing sites and accessing specific content. You won’t need to list the web directories if you already know them.
Users may upload material to a web server on certain websites. During a pentest, this might be an excellent attack vector, as you could identify spots to upload malicious code to target the server and/or users of the online service, or important information that should be password-protected.
Whether you wanted to see if the web servers of a potential target company support an upload directory with directory indexing enabled, you might do a Google search like this:
intitle:index.of "uploads"
Using Shodan for Reconnaissance
Specialized search engines, like Google and Bing, provide a way to gather potentially sensitive information and weaknesses about a target business. They are, however, more targeted in their approach and provide even more specificity when it comes to creating search parameters for certain areas of interest.
Breach data and Internet network scanners may provide information on IP addresses, domain names, e-mail addresses, passwords, ports, services, and even operating system information.
These search engines allow enterprises to view their attack surface in terms of ports and services accessible to the Internet, as well as enabling pentesters to search data anonymously.
The following are some of the most popular specialised search engines for penetration testing in general.
Shodan
Shodan (www.shodan.io) is the world’s first search engine for Internet-connected devices, and it offers both free and paid subscriptions (with account registration).
You may query and search the Internet of Things using the Shodan web interface or the application programming interface (API) inside other tools after you’ve created an account (IoT).
Some of the search possibilities available via the online interface should be known to you. The Shodan search bar works similarly to the Google Search text box in that it allows you to query keywords and phrases.
When you search for ftp, the results are organised into distinct groups under the following headings:
- Top Countries
- Top Services
- Top Organizations
- Top Operating Systems
- Top Products
Shodan keyword search
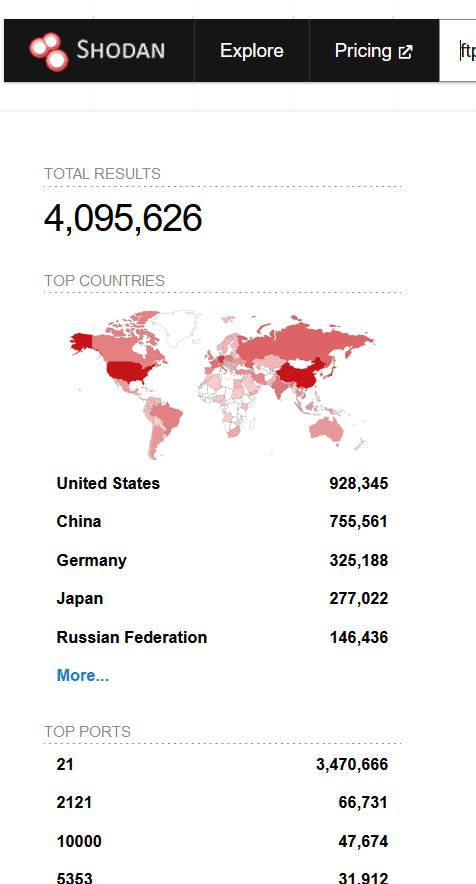
Hovering your cursor over the summary results shown under each of the categories in your web browser will reveal that each result is a hyperlink. Shodan will apply the necessary search filter to the search box and conduct the query if you click FTP under the Top Services category.
These search criteria, like those in Google Search, can help you dig down into the data to discover the information you’re searching for.
If you already have a list of targets in mind, you may use the search field to look for the IP address. If Shodan has information on the destination IP address, the query may provide information such as geographic location data (i.e., city, country, organisation, ISP, and so on), network ports and services, and banner data.
Censys
Censys was developed by the same security researchers that developed ZMap in 2015 at the University of Michigan. The ZMap Project (https://zmap.io) offers essential data and tools for large-scale, Internet-wide scanning and measuring.
Censys (https://censys.io), like Shodan, is a specialised search engine that keeps track of public Internet research data and provides a web-based user interface for searching data sets including IPv4 addresses, websites, and web certificates.
The following links will take you straight to the search interface for each of these data sets on the Censys website:
- IPv4 hosts https://censys.io/ipv4
- Websites https://censys.io/domain
- Certificates https://censys.io/certificates
The data in Censys is organised into fields. These parameters may be used as filters to narrow down certain areas of interest. When utilising the IPv4 data set, for example, you may search for ftp and then click the 21/ftp link to apply the particular protocol filter, which would only reveal ports that match 21 and FTP detected in the data set.
You may use the optional Boolean logic operators AND, OR, and NOT to combine numerous statements inside your query to narrow down your search parameters.
If you know the IP address of the target you’re looking for, you may run a query against the IPv4 data set using the IP address. a query against the IP address example.com It’s possible to get the same fundamental information that Shodan did. When you click the Details button, you’ll get more information about the port that was returned in the result.
Although Censys and Shodan have similar capabilities and features, it’s a good idea to utilise both to ensure the integrity of the data returned by your queries.
Conclusion
DNS records may include information about individual domain assets such as the fully qualified domain name (FQDN) and IP address. A DNS resolver, a DNS root server, and an authoritative DNS server are the three kinds of DNS servers.
DNS speeds up domain name resolution by removing the requirement for an organization’s DNS server to contact the target domain’s authoritative server to resolve the IP address for the hostname.
Knowing which external websites, apps, and/or resources a business allows its users access to might help you increase your chances of success. You may perform further DNS research and exploit DNS zone transfer vulnerabilities using commands like dig. Dig is a versatile tool for querying DNS name servers.
Using Google search operators can help you narrow the search criteria for your target. For example, you might use the following syntax to run a Google search for.edu (educational) websites that have a PowerPoint file:. \r\rsite:.edu filetype:ppt.
The robots.txt file gives crawlers specific “Disallow” instructions to restrict them from crawling the website. This information might aid in narrowing the attack surface against a target web server.
Specialised search engines provide a way to gather potentially sensitive information and weaknesses about a target business. You may query and search the Internet of Things using the Shodan web interface or the application programming interface (API) inside other tools after you’ve created an account.
Related Posts


